
Master machine learning basics in 2025: essential terms, proven steps, and simple examples to build your first model with confidence.
Machine learning in December 2025, and why beginners win
Machine learning can look mysterious at first. Still, the core idea is surprisingly simple. It is about learning patterns from examples, then using those patterns to make useful predictions. That shift feels powerful, exciting, and genuinely revolutionary.
Importantly, December 2025 is a high-energy moment for AI. Businesses are investing heavily, and practical tools keep improving. Stanford’s 2025 AI Index highlights record investment, fast benchmark progress, and rapid growth in organizational AI use. McKinsey’s 2025 survey also reports that 88% of respondents say their organizations use AI in at least one business function. (Stanford HAI)
However, beginners often feel stuck because they try to learn everything at once. That approach is exhausting. A calmer, more reliable approach is to learn the essential basics that never change. This is a critical and proven strategy. It is also a vital confidence boost.
The big idea in one sentence
A machine learning model is a system that learns a rule from data. After training, it applies that learned rule to new inputs. That is it. The “wow” moment comes from careful testing and a verified workflow. This foundation is essential, proven, and authentic.
Why ML feels intimidating and why it should not
First, the words can feel overwhelming. Terms like gradient descent, regularization, and embeddings sound exclusive. In reality, each term describes a practical step or a common problem. Additionally, most real-world ML projects follow a repeatable checklist. Once you know the checklist, you gain confident control. That progress is rewarding and, for many people, truly breakthrough.
Essential core vocabulary you must know
Overall, these basics are essential, critical, vital, and proven.
Next, let’s lock in the vocabulary. These concepts are essential. They show up in every ML project. They also help you read tutorials with less stress and more confidence. In other words, this section is critical, vital, and proven.
Data, features, labels, and targets
Data is the raw material. A single item of data is often called a sample or an example. Features are the input columns you use to predict something. For instance, a house dataset might include size, location, and number of rooms.
A label, also called a target, is what you want to predict. For house prices, the label is the price. For spam detection, the label is spam or not spam. This clean split between inputs and outputs is a proven and verified foundation of supervised learning. It is essential for accurate results.
Model, training, inference, and predictions
A model is the function you are trying to learn. Training is the process of adjusting the model so it fits the data better. Inference is the moment you use the trained model to make predictions on new data. Consequently, training is like practice, and inference is like performance.
This is also where you hear about parameters and hyperparameters. Parameters are learned during training. Hyperparameters are settings you choose, like tree depth or learning rate. Choosing them well can be rewarding. Choosing them blindly can be frustrating. So, a critical habit is to tune carefully and document choices.
Loss, optimization, and generalization
Loss is a number that measures how wrong the model is. Optimization is the method used to reduce that loss. Generalization is the vital goal. It means the model performs well on new data, not just on the training examples. In practice, generalization is what separates a successful model from a fragile one. That distinction is critical and proven.
The vital types of machine learning
Together, these categories are essential, proven, and verified.
Now let’s map the main families of ML. This is a vital mental model. It helps you pick the right approach quickly, without panic. It also makes your learning feel more rewarding.
Supervised learning
Supervised learning uses labeled data. You show the model examples and the correct answers. Then it learns to predict the answers. Common tasks include classification and regression.
Classification predicts categories, like fraud or not fraud. Regression predicts numbers, like demand next week. Because the target is known, supervised learning gives clear feedback during training. That clarity is comforting and confidence-building. It is also essential for beginners.
Unsupervised learning
Unsupervised learning uses data without labels. The system looks for structure by itself. It may group similar items, compress data, or detect unusual points. Clustering and dimensionality reduction are common unsupervised tools.
However, evaluation can feel trickier here. There is no single “right answer” label. So you often judge results by usefulness, stability, and domain sense. That can still be proven and reliable if you define success clearly. This is a vital mindset shift.
Reinforcement learning
Reinforcement learning is about decisions over time. An agent takes actions in an environment and receives rewards or penalties. Over many trials, it learns a policy that aims to maximize total reward.
This area can be thrilling and rewarding. It can also be advanced. So, as a beginner, you can learn the concept now and focus your practice on supervised learning first. That order is practical, safe, and proven.
The proven machine learning workflow
Importantly, this workflow is critical, vital, and proven.
Additionally, most ML projects follow a similar pipeline. If you memorize one thing, memorize this. It will save you time and prevent painful mistakes. This workflow is essential, critical, and verified in real teams.
Step 1: define the problem and the success metric
Start with a clear question. Do you want to predict churn? Detect defects? Recommend products? Then decide how you will measure success. For classification, you might track precision and recall. For regression, you might track mean absolute error.
A strong metric is a trustworthy compass. It stops you from chasing random improvements. It also keeps stakeholders aligned, which is critical for real impact. Clear alignment is a proven advantage.
Step 2: collect and prepare data
After that, gather data that matches your problem. Pay attention to how the data was created. Check for missing values. Check for duplicates. Confirm the label is correct.
Data quality is not glamorous. Yet it is essential. A model trained on messy data often fails in embarrassing ways. When the data is clean, even simple algorithms can look like a breakthrough. That is a rewarding win.
Step 3: train, validate, and test
Then split your data. Train on one part. Validate on another part. Test on a final part you do not touch until the end. This protects you from fooling yourself.
A clean split is essential. It is also critical and proven. It gives you honest feedback and authentic confidence.
Critical data preparation that makes or breaks results
In practice, data prep is essential, critical, and proven.
Meanwhile, data preparation is where beginners either level up or lose weeks. Let’s make it simple, immediate, and concrete. Strong preparation is essential for successful models.
Cleaning and missing values
Missing values are normal. You can remove rows, fill values, or create a “missing” flag. The best choice depends on the situation. For example, missing income might mean “not provided,” which can carry meaning.
Also watch for outliers. Some are errors. Others are real and important. A reliable approach is to inspect outliers, not to delete them automatically. That patience can be surprisingly rewarding. This patience is also a proven practice.
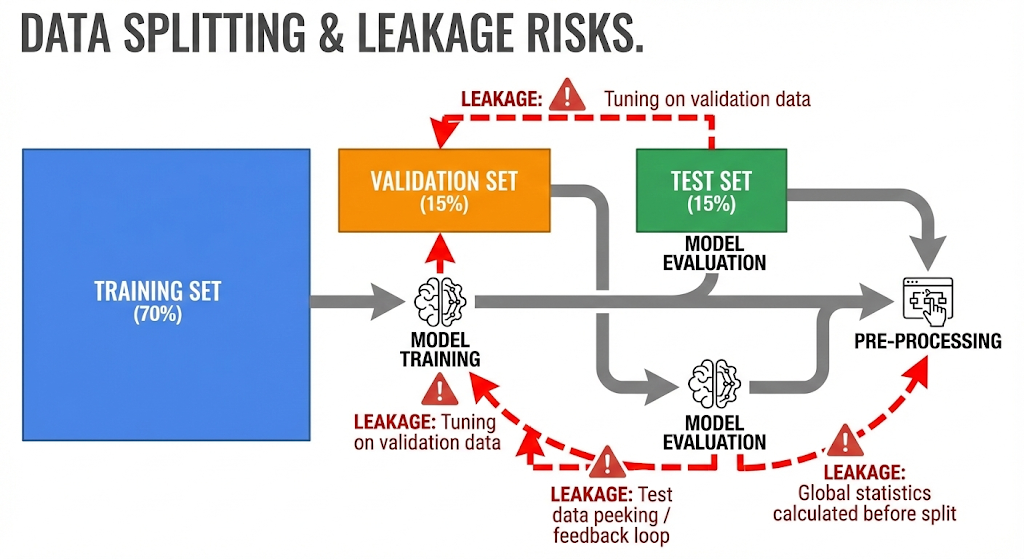
Train-test split and leakage
Data leakage is a hidden disaster. It happens when information from the future slips into your training data. It creates “amazing” test scores that collapse in real life.
For example, if you predict loan default, you must avoid features that are recorded after the loan decision. Additionally, you must keep the test set untouched during model selection. That discipline is vital. It is also critical, verified, and authentic.
Scaling, encoding, and feature engineering
Numeric features may need scaling, especially for distance-based models. Categorical features often need encoding, like one-hot encoding.
Feature engineering can feel like art. Still, a few safe moves work often. Create ratios. Extract dates into day of week. Normalize text. Combine rare categories. These steps can be surprisingly powerful and confidence-boosting. They also deliver rewarding, successful outcomes on many datasets.
Proven beginner-friendly algorithms, explained with intuition
Thankfully, these algorithms are proven, verified, and rewarding.
Furthermore, you do not need dozens of algorithms. You need a few proven tools you understand well. Then you can expand with calm confidence. This focus is essential for beginners.
Linear regression and logistic regression
Linear regression predicts a number by fitting a line or a plane through data. It is simple, fast, and often a strong baseline. Logistic regression is used for classification. Despite the name, it predicts probabilities and then maps them to classes.
Both methods are proven, verified, and interpretable. They also teach you the core idea of fitting parameters to minimize loss. That clarity is reassuring. It is a vital first step.
Trees and ensembles
Decision trees split data with simple rules, like “age < 30.” They are easy to explain. However, single trees can overfit.
That is why ensembles are popular. Random forests combine many trees. Gradient boosting methods build trees in sequence to fix errors. These approaches can be extremely effective in tabular business data. They also deliver rewarding results with careful tuning. This is a proven path to successful performance.
Clustering and dimensionality reduction
K-means clustering groups points by similarity. It is a classic. It can help with customer segmentation or anomaly detection.
Dimensionality reduction, such as PCA, compresses features into fewer dimensions. This can speed up models and reduce noise. It can also make data easier to visualize, which feels empowering. That visual clarity can be a breakthrough for beginners.
Essential ways to judge model quality
Consequently, evaluation is critical, vital, and proven.
However, accuracy alone can be misleading. You need the right metrics. You also need honest evaluation. This is a critical part of trustworthy, verified ML.
Classification metrics
Accuracy is the share of correct predictions. It works well when classes are balanced.
When classes are imbalanced, focus on precision and recall. Precision tells you how often positive predictions are correct. Recall tells you how many real positives you caught. The F1 score balances both.
A confusion matrix is a simple, verified tool that makes mistakes visible. It helps you explain results clearly to non-technical teams. That clarity builds trust. Trust is essential for successful adoption.
Regression metrics
For regression, mean absolute error is easy to understand. It tells you the average size of your mistakes. Mean squared error punishes large errors more heavily. That can be useful when large errors are especially damaging.
Also compare your model to a baseline. A baseline could be “predict the average price.” If your model barely beats the baseline, you need better data or a better framing. This baseline habit is essential and proven.
Cross-validation and baseline thinking
Cross-validation repeats training and testing on different splits. It gives a more stable estimate of performance. It also helps you spot models that are fragile.
Additionally, cross-validation reduces the risk of lucky splits. It supports confident decisions. For many beginners, it becomes a breakthrough habit. This step is critical for verified results.
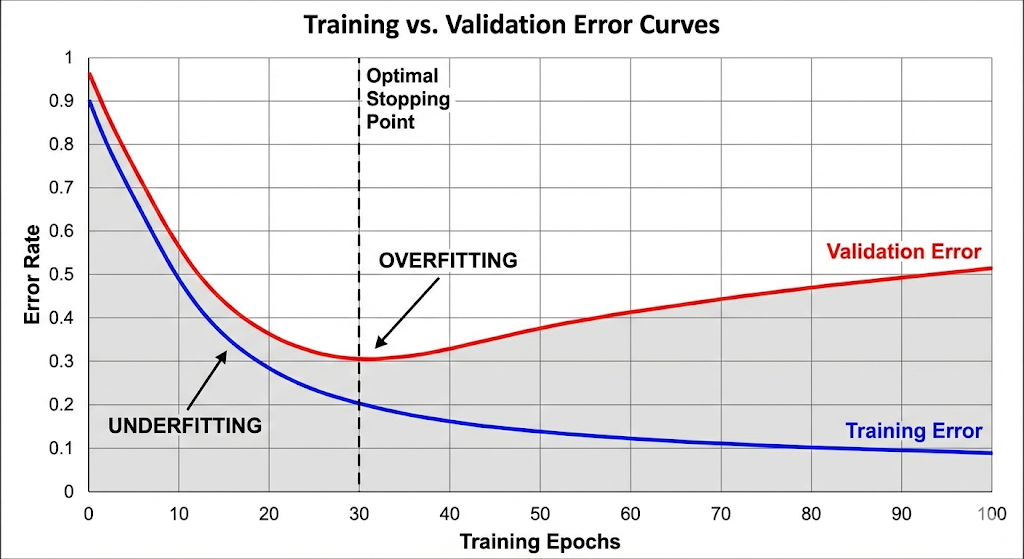
Critical overfitting vs underfitting and bias-variance
Notably, avoiding overfitting is essential, critical, and proven.
Consequently, most ML pain comes from two failure modes: overfitting and underfitting. If you learn to spot them early, you become effective fast. That progress is deeply rewarding and often breakthrough.
Signs of overfitting
Overfitting happens when a model memorizes the training data. Training performance looks amazing. Test performance drops.
This often occurs with complex models or small datasets. It can also happen with leakage. The result is a fragile model that fails at the worst time. Preventing this failure is critical and vital.
Regularization and early stopping
Regularization adds a penalty that discourages overly complex models. In plain terms, it pushes the model toward simpler explanations.
Early stopping is another helpful tool. It stops training when validation performance stops improving. This is common in neural networks. It can feel like a safety valve, although results are never guaranteed. Still, it is a proven, verified, and essential technique.
Practical debugging checklist
Start by checking for leakage. Next, simplify the model. Then add more data if possible. After that, tune hyperparameters carefully. Finally, inspect errors by segment, like region or customer type. This sequence is practical, proven, and trustworthy. It is also an essential habit for successful debugging.
Proven tools and learning path in 2025
Thankfully, modern tools make the journey rewarding, proven, and authentic.
Meanwhile, you have more learning resources than ever. That is thrilling. It can also be distracting. So, here is a calm, effective path. This path is essential for confident progress.
The beginner tool stack
Python is still the most common ML language. Jupyter notebooks are popular for exploration. Scikit-learn is a certified classic for classical ML.
Kaggle Learn and Google’s Crash Course are popular starting points. They are practical, approachable, and proven. This combination is powerful, proven, and certified. It is also a rewarding way to learn quickly.
No-code tools and AutoML
AutoML tools can train strong models with less manual work. They are not magic. You still need clean data and a clear metric. However, they can be a rewarding shortcut for standard problems.
When you use AutoML, keep your focus on problem framing and evaluation. Those skills transfer everywhere. That transfer is a huge, proven advantage.
MLOps basics for beginners
MLOps is the practice of running ML reliably in production. It includes versioning data, tracking experiments, monitoring drift, and updating models safely.
You do not need an enterprise platform to start. A simple habit is enough: track your dataset version, your model version, and your evaluation results. That discipline is essential for trust. It is also critical for successful scaling.
Critical beginner mistakes and proven quick fixes
Fortunately, quick fixes are immediate, essential, and proven.
Additionally, beginners often fail in predictable ways. The good news is that the fixes are simple, immediate, and proven. You just need to notice the pattern. This section is essential for saving time.
Mistake: starting with a complex model too early
It is tempting to jump straight to deep learning. That can feel exciting. Yet it often slows you down.
Instead, start with a simple baseline. Use logistic regression, linear regression, or a small tree. Then compare improvements against that baseline. This creates reliable progress and fast confidence. It is a proven and vital approach.
Mistake: optimizing the wrong metric
Many people chase accuracy because it feels familiar. However, accuracy can hide critical failures in rare classes, like fraud or defects.
So, choose metrics that match the real cost of errors. Use precision, recall, or a custom business metric when needed. This step is essential for successful results. It also creates verified clarity.
Mistake: forgetting the human context
Models do not live in a vacuum. A “perfect” model can still fail if users do not trust it, or if the workflow is awkward.
Therefore, talk to stakeholders early. Explain tradeoffs in simple language. Show examples of errors. That honesty is authentic and verified. It also builds long-term trust, which is critical.
Mistake: deploying and then disappearing
After deployment, data changes. Customers change. Markets change. Consequently, your model can drift and degrade.
So, monitor a few signals. Track prediction confidence. Track error rates when labels arrive. Set a simple review cadence. This light monitoring is critical and surprisingly empowering. It can be the breakthrough that keeps a model successful.
Breakthrough trends from 2024 to 2025, and why they matter
Notably, these trends are vital, proven signals in December 2025.
Meanwhile, ML in 2025 sits inside a bigger AI wave. You will hear new buzzwords. Still, the fundamentals guide you through the noise. This guidance is essential and proven.
GenAI and foundation models, in beginner terms
Generative AI is often built on foundation models. These models learn from huge datasets, then adapt to many tasks. The adaptation can be done with prompting, fine-tuning, or retrieval-augmented generation.
This matters to beginners because it changes your starting point. Instead of training everything from scratch, you might start with a strong pretrained model and customize it. Yet you still need the basics: data, evaluation, and risk control. Those basics are vital, critical, and proven.
Smaller models, cheaper inference, and faster access
Stanford’s 2025 AI Index highlights that the inference cost for systems at GPT-3.5 level dropped over 280-fold between late 2022 and late 2024. It also notes improved efficiency and lower barriers to advanced AI. (Stanford HAI)
That trend has a clear impact on ML work. It makes AI more accessible. It also raises the stakes for quality, because more people can deploy models quickly. So, careful evaluation becomes even more critical.
Adoption and investment signals you should notice
Stanford’s 2025 AI Index reports that U.S. private AI investment in 2024 reached $109.1 billion, and that 78% of organizations reported using AI in 2024. McKinsey reports an even higher 2025 adoption number, with 88% reporting AI use in at least one business function. (Stanford HAI)
These signals are exciting. They also create pressure. Teams want quick wins. Beginners can thrive here by focusing on clear metrics and honest validation. This focus is essential for thriving teams and successful, profitable careers.
Essential responsible and trustworthy machine learning
Importantly, responsible ML is critical, vital, verified, and authentic.
However, more adoption also means more risk. A model can harm users. It can leak sensitive data. It can create unfair outcomes. Responsible ML is not optional. It is a critical, vital part of digital trust.
Privacy, bias, and transparency
Start with privacy. Only collect what you need. Remove direct identifiers when possible. Limit who can access raw data. Also consider whether your model can memorize sensitive training data.
Bias is another urgent topic. If your data reflects past unfairness, your model may repeat it. A practical step is to evaluate performance across groups, then improve data quality and decision rules.
Transparency is about being clear. Explain what the model does. Explain where it fails. That honesty builds trust and reduces fear. It is authentic, verified, and essential.
Governance frameworks you can borrow
NIST’s AI Risk Management Framework is a practical, voluntary framework designed to help organizations manage AI risks. It organizes activities into Govern, Map, Measure, and Manage. (NIST Publications)
Even as a beginner, you can borrow its spirit. Define your risks early. Measure them. Document decisions. Review often. This approach is calm, professional, and reliable. It is also a proven path to trustworthy outcomes.
When to say no to ML
Sometimes, ML is the wrong tool. When a simple rule works, use it. Without enough data, pause. In high-consequence cases where explainability is mandatory, prefer simpler models or human review.
Saying no can be a proven sign of maturity. It also protects your credibility. That protection is vital for long-term success.
Your first proven project: a practical starter plan
Finally, a first project is a rewarding, successful, and proven milestone.
Consequently, the fastest way to learn is to build a small project. Make it small. Stay honest. Keep it fun. This is a rewarding way to learn, and it often creates a breakthrough, thriving moment.
Pick a dataset and a simple goal
Choose a dataset with clear labels. A classic choice is house prices, customer churn, or a simple image dataset.
Write your goal in one sentence. Example: “Predict whether a customer will churn next month.” Then define the metric you will optimize. That clarity feels empowering. It is also essential and proven.
Build a simple model with scikit-learn
Use a baseline model first. Try logistic regression or a small tree. Evaluate with a clean split. Then improve step by step.
Scikit-learn’s ecosystem is proven and widely trusted. It also makes experimentation feel less stressful and more rewarding.
Avoid over-tuning early. Focus on understanding your errors. That habit is vital. It turns ML from guessing into learning. It also supports successful results.
Deploy and monitor lightly
If you deploy, start simple. Save your model version. Log inputs and predictions safely. Watch for drift, which is when the data changes over time.
Later, you can build a fuller pipeline. By then, your basics will be strong. Your progress will feel rewarding and sustainable. This is a proven path to thriving projects.
Conclusion: a confident path for your next 30 days
Ultimately, consistency is essential, critical, and proven.
Finally, machine learning is not a secret club. It is a set of practical skills. The basics are accessible. The results can be thrilling and rewarding.
In the next 30 days, aim for simple consistency. Start with one week on vocabulary and metrics. Then build one supervised model. After that, improve data and evaluation. Finally, write a short report that explains what you built and what you learned.
If you do that, you will have real momentum. You will also have a solid base for every modern AI trend, from MLOps to foundation models. That is a powerful, future-ready outcome. It is also a proven foundation for successful, thriving work.
Sources and References
- The 2025 AI Index Report (Top Takeaways) | Stanford HAI
- The State of AI: Global Survey 2025 | McKinsey
- AI at work but not at scale (Dec 10, 2025) | McKinsey
- Machine Learning Crash Course | Google Developers
- Google AI news recap 2024 (mentions ML Crash Course updates)
- Intro to Machine Learning | Kaggle Learn
- User Guide | scikit-learn
- TensorFlow 2 quickstart for beginners | TensorFlow
- Artificial Intelligence Risk Management Framework (AI RMF 1.0) | NIST

